 Intelligent Routing · Blog
Intelligent Routing · Blog
Order Column in Spreadsheets
Introduction
At Intelligent Routing, we work with a lot of data from diverse sources. Often the first step to get a feel for a data source is to get some samples into a spreadsheet. For most data-sets, the analysis process starts with the addition of an “Original Order” and “Processed Order” column to the data. From here we want our two columns to interfere as little as possible with the analysis and cleanup.
To keep track of row order during spreadsheet analysis a formula that does not give #REF! and #VALUE! errors on deleting and sorting are handy. This post shows why it is a good idea to use a robust formula like
=IFERROR(INDIRECT(ADDRESS(ROW()-1,COLUMN()))+1,1)for automated calculation of the processed order column.
If you want to follow along in LibreOffice Calc or Excel® you can download the example file.
Why
Tagging the original and processed row order along with data can give some valuable insights in downstream analysis. If one can ensure that the processed order column is updated during the analysis without #VALUE! or #REF! Errors when the data is sorted and edited, this can save a lot of trouble for the data analyst. Apart from assisting with sequence based calculations in the spreadsheet, the original and processed order columns help when capturing the cleanup process into scripts later on.
Many error states in raw data are position dependent. If the original order is not saved, the cleanup process often hides this dependency to downstream analysis.
How
Original Order
For “Original Order” we follow the Excel®/Calc basic fill-down sequence:
- before any other edits, insert a column,
- name it, e.g. “Original Order”,
- start with 1 and 2 as the first two-row values and select them,
- fill the text down (i.e. double-click the bottom right corner of the selection or drag down for the full range if there are gaps in the data).
Now any order updates that happen as part of the analysis will include the row’s original position as reference. The “Original Order” column won’t give problems when editing since the values move along with the rows when they are sorted. Also, because it is a value only column, no #REF! errors appear when a row is deleted.
To get the same independence for the “Processed Order” column, we need to disconnect the formula’s cell references. We can achieve this via an INDIRECT(ADDRESS()) formula.
An Independent Order Column Formula
A robust formula for the order column that is also position independent is given below. If there are comments added in rows before a table the order will continue to start at 1.
=IFERROR(INDIRECT(ADDRESS(ROW()-1,COLUMN()))+1,1)Header independent (e.g. some rows at start of sheet with descriptions)
If there are no header changes expected, the simplest option for well-formed tabular data is to use the built-in row number:
=ROW()-1By Row (assuming one header row)
Both formulas are fairly robust since they don’t depend directly on other cell addresses Thus, deleting rows and sorting the data won’t influence the order result.
Watch out if a row is added mid-data: For both formulas the order column needs to be copied from any other cell in that column.
Comparison Summary
| Order Column | Cell content | Advantages | Problems when processing |
| Original Order | Numbers all the way down by dragging/double-clicking the fill handle | Works well for the original order, good reference. | This is the original order. Also if the data has gaps one needs to fill down by dragging, not double-clicking. |
| Basic |
1 in the first row and a formula below that adds 1 to the previous cell. e.g. E3 contains the formula E2+1 |
Easier to update than Original order (after entering for the first time, just double-click on the fill down handle). No need to add two formulas when generating. | The two edits and fill down are needed (first line for start and formula for a rest) each time the data is sorted/edited/deleted. |
| Error protected |
All cells contain the formula adding one to the previous value protected by an IFERROR for the first cell which defaults to 1. E.g. E2 contains the formula =IFERROR(E1+1,1) |
Easier to update than Original order (after entering for the first time, just double-click on the fill down handle). No need to add two formulas when generating. | One edit and fill down is needed each time the data is sorted/edited/deleted. |
| Independent Order |
All cells contain the formula =IFERROR(INDIRECT(ADDRESS(ROW()-1,COLUMN()))+1,1) |
One formula immune to all operations except row inserts. Immune to adding additional rows(e.g. headers) to the top of the sheet. | If a row is inserted, the formula must be added to the column to prevent the numbers from restarting. |
| Independent By Row |
All cells contain the formula =ROW()-1 |
One formula immune to all operations except header inserts and inserts. | If a row is inserted, the formula must be added to the column to prevent a gap in the numbers. If a header row is added ROW()-x must be adjusted accordingly. |
Example: Independent Order Column Compared to Other Options
The example file contains two sentences divided into German and English components. The shared components like spaces and punctuation are marked as “English and German”. There are some errors in the original file. Examples include incorrect word order, incorrect words and incorrect punctuation. The idea is to simulate an example of context-based data cleanup. After editing the file as one would do in an analysis situation, the issues mentioned with the different order columns show up. Here is a screenshot of what one can expect. Note the #VALUE! and #REF! errors. The guard of ISERROR() is not enough to catch the hidden #REF! the error that was introduced by the row delete (F30). The error now shows up as a restarted count. The Independent Order column, with
=IFERROR(INDIRECT(ADDRESS(ROW()-1,COLUMN()))+1,1)as the formula, is the only one that survived. The row delete, column sort and the addition of two header rows influenced all the other column order formulas.
A quick calculation on the original and final position was done in the header area. The calculation shows that the English sentence needed more row moves than the German sentence. Also, a formula was added to extract the original sentences from the data.
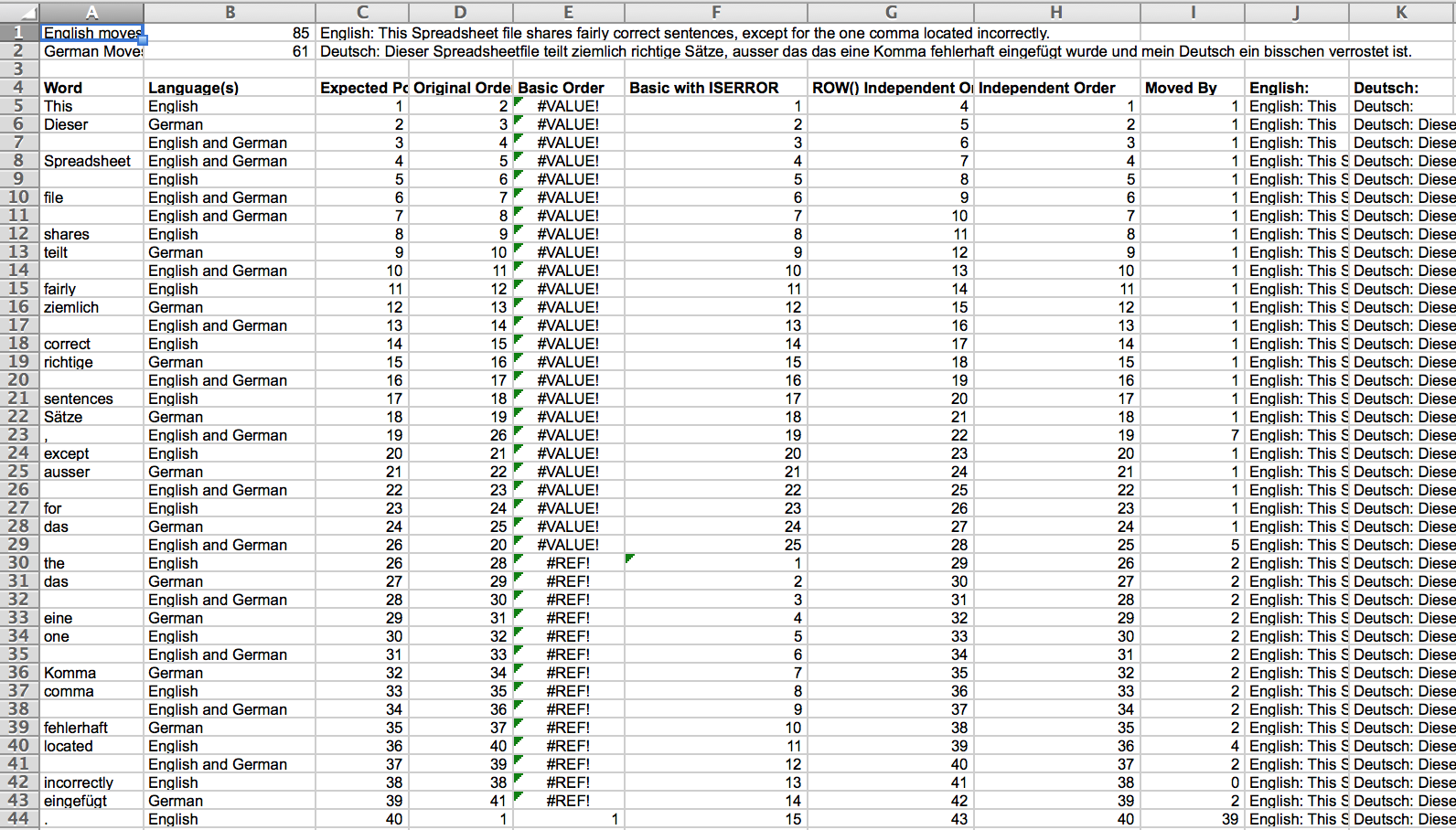
Screenshot of how the different “Order Columns” perform after one deleted the row, a column sort and the addition of header rows.
You can download the example file from the link below if you want to follow along in Excel® or LibreOffice Calc.
Tip Example File – Independent row order column in Excel®.
Excel® is a registered trademark of Microsoft Corporation in the United States and other countries.
Written by the Intelligent Routing team who work hard to make vehicle route optimization software available to every business that runs a fleet.
You should follow them on Twitter